Digit Classification Exercise using Deep Learning
In this exercise, we will train our own deep learning model to solve the widely known task of digit classification. In order to do so, the trained model has to match the input and output specifications described in this documentation. The input model must be provided in ONNX format, which we will talk about in the following sections.
Note: If you haven’t, take a look at the user guide to understand how the installation is made, how to launch a RoboticsBackend and how to perform the exercises.
Exercise Instructions
- The uploaded model should adhere to the following input/output specifications, please keep that in mind while building your model.
- The model must accept as input grayscale images with size 28x28 pixels. Input shape:
[batch_size, num_channels, height, width] = [1, 1, 28, 28] - The output must be size 10 array with the probabilities for each class. Output shape:
[batch_size, num_classes] = [1, 10]
- The model must accept as input grayscale images with size 28x28 pixels. Input shape:
- The user can train their model in any framework of their choice and export it to the ONNX format [1]. Refer to this article to know more about how to export your model. For instance, if you are working with PyTorch [2]:
import torch model = ... dummy_input = torch.randn(1, 1, 28, 28) torch.onnx.export( model, dummy_input, "mnist_cnn.onnx", verbose=True, export_params=True, input_names=['input'], output_names=['output'] )
Theory
Digit classification is a classic toy example for validating machine and deep learning models. More specifically, the MNIST database of handwritten digits [3] is one of the most popular benchmarks in the literature and is widely used in tutorials as a starting point for machine learning practitioners. For solving this exercise, it is highly recommended training your model using this database.

Image classification can be achieved using classic machine learning algorithms like SVMs or Decision Trees [4]. However, these algorithms cannot compete in performance with Convolutional Neural Networks (CNNs). CNNs are a particular class of deep neural network which takes advantage of the spatial relationship between variables that are close to each other, allowing for translation invariance. In that way, they are specially suitable for processing grid-like data, such as pixels in an image or time-steps in an audio signal. CNNs are formed by subsequent convolutional layers, each of them composed of convolutional filters. The number of layers and filters has a great impact on the performance on the model, and the optimal configuration depends mostly on the particular task and the available computational resources. Other basic building blocks in CNNs are fully connected layers, activation functions and regularization strategies, such as dropout or pooling. If you are not familiarized with these concepts, here is a nice article to warm up.
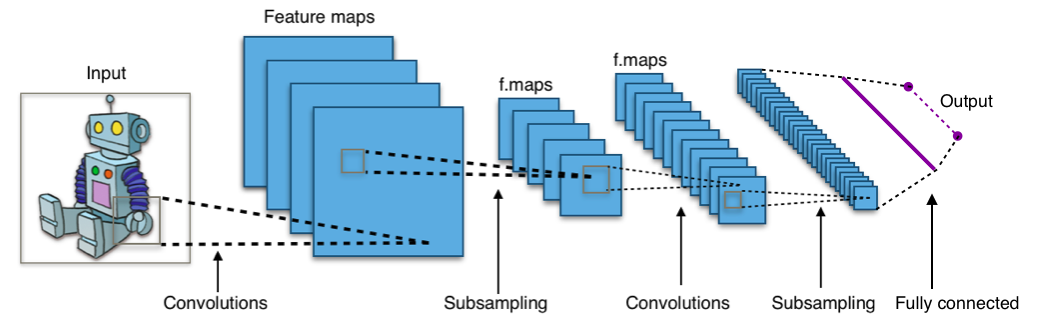
For solving the particular task of digit classification, we don’t need complex architectures. Here is an example of how you can build a CNN and train a model using MNIST database with Pytorch: Basic MNIST Example. If you want to further improve the accuracy of your model, try increasing the number of layers and play around with different regularization strategies, such as data augmentation [5].
Contributors
- Contributors: David Pascual, Shashwat Dalakoti
- Maintained by David Pascual